
Тренировка модели нейронной сети — это не только увлекательный, но и ответственный процесс, требующий проверки и тестирования полученных результатов. Таким образом, помимо тренировочных данных (train data), для объективной оценки качества построенной модели и получения предсказаний на «свежих» данных, используются валидационные и тестовые выборки — validation data и test data. Однако, зачастую, для разработки модели мы получаем лишь одну папку с файлами, разделенными на классы (в случае решения задачи классификации). А нам бы хотелось получить 3 папки с названиями «train», «val» и «test» так, чтобы, например, в трейне было 65% данных, а в «val» и «test» — по 20% и 15% соответственно. А еще лучше, чтобы эти данные были выбраны случайным образом из общей массы. И, кстати, неплохо бы иметь возможность воспроизводить этот случайный порядок в будущем — вдруг «рандомный бог» создаст идеальные случайные выборки, на которых нам захочется демонстрировать работу своей модели ещё и ещё! К счастью, в Python существует замечательный модуль под названием split-folders, с помощью которого можно быстро разделить датасет на тренировочную, валидационную и тестовую выборки!
Разбиваем датасет с помощью split-folders!
Загружаем данные
Прежде всего, подготовим исходный датасет. В качестве примера я буду использовать демонстрационный датасет под названием «faces» с мужскими и женскими лицами. Датасет можно скачать по ссылке: faces.
Итак, после загрузки данных у меня в наличии:
- Папка под названием «faces»
- В папке «faces» — 2 папки: «man» и «woman» с фотографиями мужских и женских лиц соответственно:
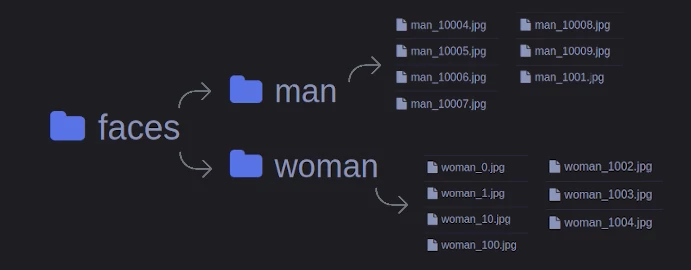
Формулируем задачу
Требуется: из исходных фотографий сформировать папку под названием «faces_splited» со следующим содержанием:
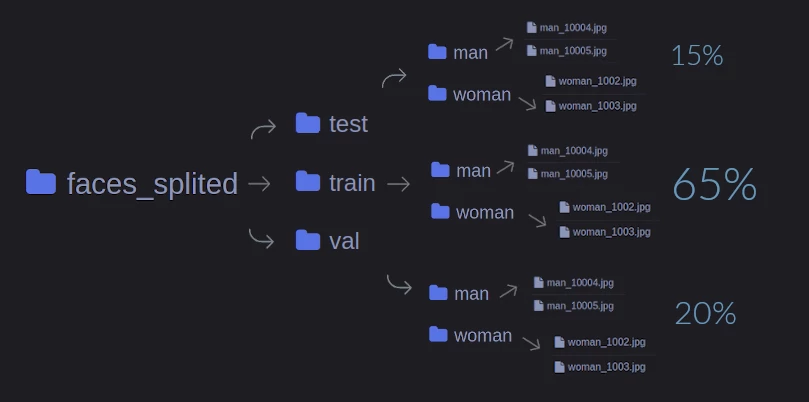
В папке «train» будет находиться 65% случайно выбранных исходных данных, в папках «validation» и «test» — по 20% и 15% соответственно.
Узнаем, как разделить датасет с помощью функции splitfolders.ratio
1. Для начала установим модуль split-folders с помощью команды:
pip install split-folders
Для установки модуля из Jupiter Notebook наберите:
!pip install split-folders
# или, в зависимости от версии и настроек Python:
!pip3 install split-folders
2. Импортируем модуль split-folders:
import splitfolders
3. Вызываем метод splitfolders.ratio:
# импортируем модуль
import splitfolders
# определяем путь к папке с исходными файлами
input_folder = "faces" # у вас путь может быть другим
# разбиваем датасет на папки с процентным соотношением числа файлов
splitfolders.ratio(input_folder, 'faces_splited', ratio = (0.65, 0.2, 0.15), seed=13, group_prefix=None)
Значения параметров в splitfolders.ratio:
input_folder — путь к папке с исходными файлами. Он определен до вызова метода splitfolders.ratio.
‘faces_splited’ — путь к папке с разделенными данными. Вы можете назвать эту папку по своему вкусу.
В параметре ratio перечислено, какой процент исходных данных будет содержаться в папках «train», «val» и «test» соответственно. Все переданные в ratio значения должны находиться в промежутке [0,1]. Соответственно, нужные нам 65% будут переданы в ratio, как 0.65, 20% — как 0.2, а 15% — как 0.15.
В качестве значения параметру seed мы передаем стартовое значение для запуска алгоритма по получению списков случайных номеров фотографий, которые будут переданы в папки «train», «test» и «val». Если мы не определим параметр seed, то стартовая позиция будет выбрана случайным образом и мы не сможем воспроизвести полученный ранее результат.
Параметр group_prefix позволяет разбить файлы на группы, в зависимости от их префикса.
Разделение данных с помощью функции splitfolders.ratio может занять некоторое время, в зависимости от объема исходных данных. Однако, по завершению, вас порадует идеальный результат: 3 папки train, val и test с указанным в параметрах процентным соотношением данных!
 Фанаты BIG DATЫ — наш Телеграм-канал для всех увлеченных изучением Python, Data Science, ML, нейросетями и т.д. Присоединяйтесь, вместе веселее! 😉
Фанаты BIG DATЫ — наш Телеграм-канал для всех увлеченных изучением Python, Data Science, ML, нейросетями и т.д. Присоединяйтесь, вместе веселее! 😉
Узнаем, как разделить датасет с помощью функции splitfolders.fixed
В заключении хотелось бы отметить еще один полезный метод модуля splitfolders — fixed. С помощью функции splitfolders.fixed() можно задать фиксированное количество файлов в папках «val» и «test». Например, если нужно разбить исходный датасет так, чтобы в папке «val» находилось 50 фотографий, а в папке «test» — 10, то вызов функции будет выглядеть следующим образом:
# импортируем модуль
import splitfolders
# определяем путь к папке с исходными файлами
input_folder = "faces" # у вас путь может быть другим
# разбиваем датасет на папки с фиксированным количеством файлов
splitfolders.fixed(input_folder, 'faces_splited', fixed = (50,10), seed=13, oversample=False, group_prefix=None)
Новый параметр oversample позволяет осуществить случайную передискретизацию в случае несбалансированных данных в датасете.
А в параметре fixed задаются 2 значения: число файлов после разделения в папке «val» и число файлов в папке «train» соответственно.
Назначение других параметров было описано немного выше в пункте «Разбиваем датасет с помощью функции splitfolders.ratio» текущей статьи.
В зависимости от значений, заданных в параметре fixed, разделение датасета может занять некоторое время, однако, в результате вы получите тренировочную, валидационную и тестовую выборки в определенном вами количественном соотношении!