Решим задачу бинарной классификации изображений с помощью Keras! В качестве датасета будем использовать открытые данные, размещенные на сайте Kaggle, с фотографиями мужских и женских лиц.Скачать датасет можно по ссылке: «Фотографии мужских и женских лиц»
1. Загрузка данных
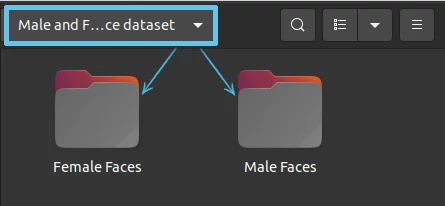
Если вы еще не скачали данные для классификации, то самое время осуществить загрузку по ссылке: «Фотографии мужских и женских лиц». Будем предполагать, что файл с кодом расположен в одной папке со скачанным датасетом. Датасет, в свою очередь, представляет собой разархивированную директорию под названием Male and Female face dataset, в которой расположены папки с мужскими и женскими лицами под названиями Male Faces и Female Faces соответственно:
После загрузки данных можно приступать к созданию нейросети! Для начала, импортируем необходимые модули.
2. Импорт необходимых модулей и библиотек
Для решения задачи классификация изображений в Keras, нам понадобятся:
- Библиотеки для работы с системными файлами и директориями, чтобы мы могли считывать имена файлов из директорий.
- Библиотеки для работы с изображениями помогут нам прочитать изображения, вывести их на экран, узнать параметры (формат или размер изображения), и т.д.
- Модули для препроцессинга и аугментации изображений. Эти модули помогут привести изображения в единый формат, а также сгенерировать новые данные для увеличения датасета.
- Объекты модели, слоев, оптимайзера для построения нейросети.
Подключим эти модули и библиотеки с помощью следующего кода:
import tensorflow as tf
from tensorflow import keras
# импортируем библиотеку pathlib, а также функцию Path для работы с директориями
import pathlib
from pathlib import Path
import os
# для упорядочивания файлов в директории
import natsort
# библиотеки для работы с изображениями
import cv2
from PIL import Image
import matplotlib.pyplot as plt
# -- Импорт для подготовки данных: --
# модуль для предварительной обработки изображений
from tensorflow.keras.preprocessing import image
# Класс ImageDataGenerator - для генерации новых изображений на основе имеющихся
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# -- Импорт для построения модели: --
# импорт слоев нейросети
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing
# импорт модели
from tensorflow.keras.models import Sequential
# импорт оптимайзера
from tensorflow.keras.optimizers import RMSprop
3.Исследование и правка данных
На данном этапе мы выведем часть фотографий на экран, а также сравним размеры фотографий и их формат. Для этого нам понадобится библиотека под названием matplotlib с коллекцией функций pyplot. Но прежде, определим пути к рабочим директориям и упорядочим фото по названиям:
# Получим и отсортируем список с названиями фото с женскими лицами
woman_filenames = os.listdir(woman_path)
woman_filenames = natsort.natsorted(woman_filenames)
# Получим и отсортируем список с названиями фото с мужскими лицами
men_filenames = os.listdir(men_path)
men_filenames = natsort.natsorted(men_filenames)
# -- Выведем часть фотографий (с 5 по 15) на экран:
#1. создаем график(фигуру) для вывода всех фото
pic_box = plt.figure(figsize=(14,12))
for i, image_name in enumerate(woman_filenames[5:15]):
#2. считываем текущее изображение
image = plt.imread(str(Path(woman_path, image_name)))
#3. создаем "подграфик" для вывода текущего изображения в заданной позиции
ax = pic_box.add_subplot(3,5,i+1)
#4. в качестве названия графика определяем имя фотографии и число каналов
ax.set_title(str(image_name) + '\n Каналов = ' + str(image.shape[2]))
#5. выводим изображение на экран
plt.imshow(image)
#6. отключаем вывод осей графика
plt.axis('off')
plt.show()
Полученный результат:

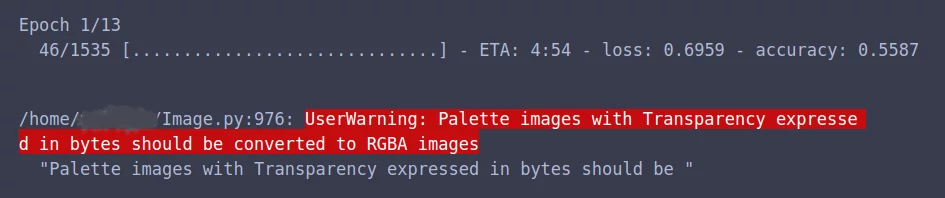
Обратите внимание, что среди фото с женскими лицами встречаются изображения jpg, jpeg и png формата. Кроме того, все изображения jpg формата имеют по 3 цветовых канала, в то время, как у фото png формата может быть как 3 («0 (3).png», «0 (5).png»), так и 4 цветовых канала(«0 (4).png»). На самом деле, png формат изображения помимо красного, зеленого и синего каналов, подразумевает наличие альфа-канала, задающего прозрачность пикселей. Keras это «знает» и при запуске нейросети, работающей с png изображениями без альфа-канала, выдает предупреждающее сообщение:
Чтобы избежать подобных сообщений, конвертируем все трех-канальные(RGB) фотографии формата png в четырехканальные (RGBA) изображения. Сначала отредактируем фото с женскими лицами:
for img in woman_filenames:
im = Image.open(Path(woman_path,img))
# Если расширение файла ".png" и формат файла "PNG":
if (img[-3:].lower()=='png' and im.format is 'PNG'):
# если режим изображения не RGBA (без альфа-канала):
if im.mode is not 'RGBA':
# конвертируем фото в RGBA и сохраняем в той же директории под тем же именем
im.convert("RGBA").save(Path(woman_path, img))
# при желании, можно вывести имена файлов, которые были переформатированы.
print(img)
После этого — отредактируем фото с мужскими лицами:
for img in os.listdir(men_path):
im = Image.open(Path(men_path,img))
# Если расширение файла ".png" и формат файла "PNG":
if (img[-3:].lower()=='png' and im.format is 'PNG'):
# если режим изображения не RGBA (без альфа-канала):
if im.mode is not 'RGBA':
# конвертируем фото в RGBA и сохраняем в той же директории под тем же именем
im.convert("RGBA").save(Path(men_path, img))
# при желании, можно вывести имена файлов, которые были переформатированы.
print(img)
4. Оптимизация и аугментация данных
Делим данные
Так как на данный момент все файлы находятся в единой директории, то потребуется выполнить разделение данных на тренировочную, тестовую и валидационную выборки. Выполним это с помощью функции:
splitfolders.ratio(base_path, 'faces_splited', ratio=(0.8, 0.15, 0.05), seed=18, group_prefix=None )
Процесс разбиения данных может занять несколько минут. Подробнее о работе splitfolders.ratio() можно почитать в статье: Как разделить датасет на тренировочную, валидационную и тестовую выборки?
Нормализуем данные
После разделения выборки, позаботимся о том, чтобы тензоры, соответствующие изображениям, имели одинаковые размеры и были представлены числами от 0 до 1 (на данный момент, это числа от 0 до 255 в соответствии с форматами RGB и RGBA). Для этого сгенерируем нормализованные трейновые и валидационные данные на основе имеющихся:
# определим параметры нормализации данных
train = ImageDataGenerator(rescale=1/255)
val = ImageDataGenerator(rescale=1/255)
# сгенерируем нормализованные данные
train_data = train.flow_from_directory('faces_splited/train', target_size=(299,299),
class_mode='binary', batch_size = 3, shuffle=True)
val_data = val.flow_from_directory('faces_splited/val', target_size=(299,299),
class_mode='binary', batch_size=3, shuffle=True)
Определяем параметры аугментации
Как известно, чем больше входных данных передается нейросети, тем лучше результат. Поэтому для улучшения результата, прямо во время обучения сети, мы будем генерировать новые данные за счет незначительных преобразований имеющихся фотографий. Для это будем использовать простые приемы, такие как: отражение по горизонтали, незначительные наклоны фото, изменение контраста и размера:
# Определяем параметры аугментации
data_augmentation = keras.Sequential(
[
# Отражение по горизонтали
layers.experimental.preprocessing.RandomFlip("horizontal", input_shape=(299, 299,3)),
# Вращение на рандомное значение до 0.05
layers.experimental.preprocessing.RandomRotation(0.05),
# Меняем контрастность изображений
layers.experimental.preprocessing.RandomContrast(0.23),
# Изменяем размер
layers.experimental.preprocessing.RandomZoom(0.2)
]
)
5. Построение и обучение модели
После подготовки данных, приступим к кульминации нашего процесса — построению модели! Отмечу, что предложенная мной модель не проходила этап тщательной подкрутки параметров и, скорее всего, может быть улучшена. Однако, даже в таком виде она показывает неплохой результат — 98% на трейне и валидации.
Так как решаемая задача является бинарной, то в качестве функции активации для выходного стоит использовать sigmoid -у. А для активных слоев можно выбрать другую функцию, например, selu. Ниже я приведу код самой модели:
model = Sequential([
# добавим аугментацию данных
data_augmentation,
layers.Conv2D(16, (3,3), activation='selu', input_shape=(299,299,3)),
layers.MaxPool2D(2,2),
layers.Conv2D(32, (3,3), activation='selu'),
layers.MaxPool2D(2,2),
layers.Dropout(0.05),
layers.Conv2D(64, (3,3), activation='selu'),
layers.MaxPool2D(2,2),
layers.Dropout(0.1),
layers.Conv2D(128, (2,2), activation='selu'),
layers.MaxPool2D(2,2),
layers.Conv2D(256, (2,2), activation='selu'),
layers.MaxPool2D(2,2),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(500, activation='selu'),
layers.Dense(1, activation='sigmoid')
])
После построения модели, скомпилируем ее. В качестве метрики будем использовать binary_accuracy, а в качестве оптимайзера — RMSprop. После компиляции запустим обучение модели на тренировочных данных:
# Файл для сохранения модели с лучшими параметрами
checkpoint_filepath = 'best_model.h5'
# Компиляция модели
model.compile(loss='binary_crossentropy',
optimizer = RMSprop(lr=0.00024),
#optimizer=tf.keras.optimizers.Adam(learning_rate=0.000244),
metrics = ['binary_accuracy'])
model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath,
monitor='val_binary_accuracy',
mode='max',
save_best_only=True)
# Тренировка модели
history = model.fit(train_data, batch_size=500, verbose=1, epochs= 35,
validation_data=val_data,
callbacks=[model_checkpoint_callback])
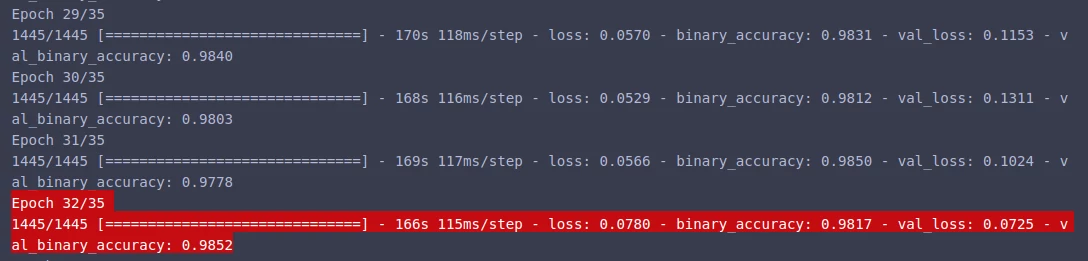
После старта обучения, уже к 32 эпохе мы получаем довольно хорошие результаты: 0.9817 на трейне и 0.9852 на валидации!