Хотите создать DataFrame, но не знаете как? Мы поделимся с Вами сразу несколькими вариантами! Однако, не бывает практики без теории, поэтому сначала — небольшой ликбез о том, что такое DataFrame и какие данные он может содержать.
Краткий ликбез о DataFrame
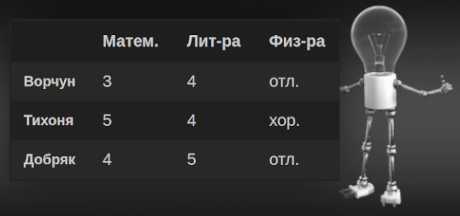
DataFrame представляет собой объект, похожий на таблицу, либо двумерную матрицу. При этом столбцы и строки таблицы могут быть именованы либо проиндексированы, а хранящиеся в DataFrame данные могут быть разных типов. На изображении ниже приведен пример DataFrame с именованными строками и столбцами, содержащий отметки учеников по разным предметам:
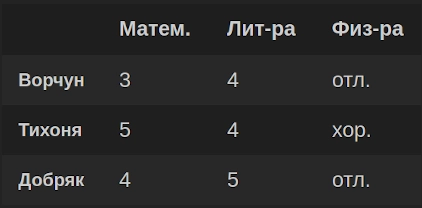
Для сравнения посмотрим, как будет выглядеть аналогичный DataFrame с пронумерованными строками и именованными столбцами:
Как же создать DataFrame ?
Существует несколько вариантов создания DataFrame. Но какой бы вариант мы ни выбрали, в основе него будет лежать конструкция:
pandas.DataFrame(data, [columns, index, type, copy])
Параметры, которые мы будем использовать:
data— (обязательный параметр) это данные, из которых планируется создать DataFramecolumns— (необязательный параметр) это список с именами столбцовindex— (необязательный параметр) это список с именами столбцов
Если параметры columns или index не определены, то столбцы и строки будут пронумерованы автоматически целыми числовыми значениями, начиная с нуля.
Узнать больше информации о параметрах pandas.DataFrame() можно из официальной документации по ссылке: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
Рассмотрим несколько наиболее практичных, на мой взгляд, вариантов создания DataFrame:
- Создание DataFrame из списка списков
- Создаем DataFrame из списка словарей
- Создаем DataFrame из numpy-массива
- Создание DataFrame из pandas.Series
Создание DataFrame из списка списков
Сначала создадим список из списков, с учетом того, что каждый вложенный список — это будущий ряд DataFrame. После этого создадим DataFrame по имени df, воспользовавшись конструкцией pd.DataFrame().
Для того, чтобы вместо имен строк выводились их индексы, нужно просто исключить определение параметра index:
import pandas as pd
# Создать список из списков
list_of_lists = [
[3, 4, 'отл.'],
[5, 4, 'хор.'],
[4, 5, 'отл.'],
]
# Создаем DataFrame
# Удалите параметр index, если вместо имен строк нужно выводить индексы:
df = pd.DataFrame(list_of_lists,
columns = ['Матем.', 'Лит-ра', 'Физ-ра'],
index = ['Ворчун', 'Тихоня', 'Добряк'])
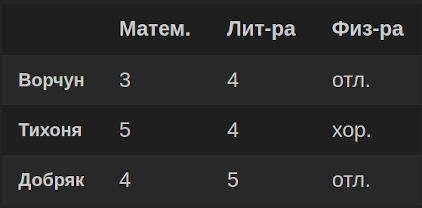
В результате получим DataFrame «df»:
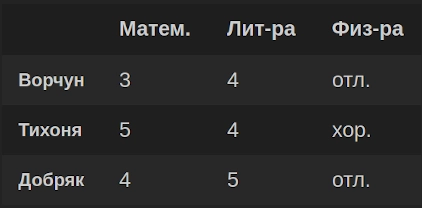
Создаем DataFrame из списка словарей
Сначала создадим список словарей с учетом того, что каждый словарь представляет собой будущую строку DataFrame. Ключами словарей являются имена столбцов DataFrame, поэтому параметр columns в pd.DataFrame() определять не нужно. Параметр index определяется, если нужно получить DataFrame с именованными строками:
import pandas as pd
# Создаем список словарей
list_of_dict = [
{'Матем.': 3, 'Лит-ра': 4, 'Физ-ра': 'отл.'},
{'Матем.': 3, 'Лит-ра': 4, 'Физ-ра': 'отл.'},
{'Матем.': 3, 'Лит-ра': 4, 'Физ-ра': 'отл.'} ]
# Удалите параметр index, если вместо имен строк нужно выводить индексы:
df = pd.DataFrame(list_of_dict, index = ['Ворчун', 'Тихоня', 'Добряк'])
Полученный DataFrame df:
Как создать DataFrame из numpy-массива?
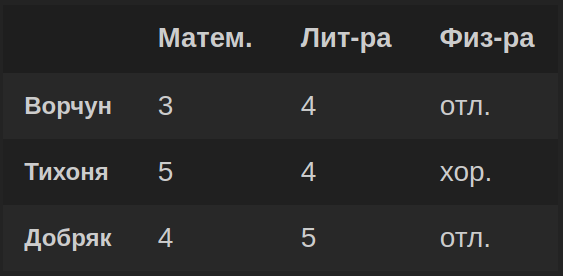
Сначала создадим numpy-массив arr так, чтобы строки массива включали в себя данные будущих столбцов DataFrame. После этого сформируем DataFrame из транспонированного массива arr.T, при необходимости зададим имена строк и столбцов в параметрах columns и index:
import pandas as pd
import numpy as np
arr = np.array([
[3, 5, 4],
[4, 4, 5],
['отл.', 'хор.', 'отл.']
])
# Удалите параметр index, если не нужны имена строк:
df = pd.DataFrame(arr.T,
columns = ['Матем.', 'Лит-ра', 'Физ-ра'],
index = ['Ворчун', 'Тихоня', 'Добряк'])
Полученный DataFrame df:
Создание DataFrame из pandas.Series
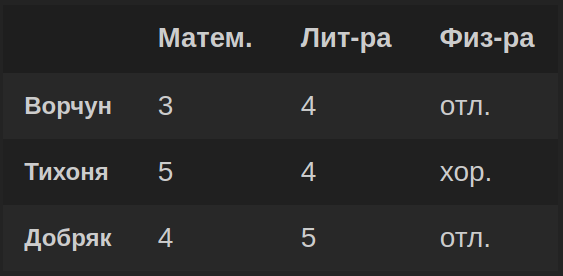
Сначала создадим одномерные структуры данных — pandas-серии, содержащие значения из будущих столбцов DataFrame. После этого из pandas-серии сформируем DataFrame df, передав при необходимости имена строк и столбцов в параметрах columns и index:
import pandas as pd
math = pd.Series([3, 5, 4])
litra = pd.Series([4, 4, 5])
fizra = pd.Series(['отл', 'хор', 'отл'])
df = pd.DataFrame((math, litra, fizra),
columns = ['Матем.', 'Лит-ра', 'Физ-ра'],
index = ['Ворчун', 'Тихоня', 'Добряк' ])
В результате выполнения кода получим DataFrame df:
Используете для работы Jupiter Notebook? Тогда Вам точно будет интресно, как сменить тему в этом редакторе: «Как сменить тему в Jupyter Notebook?».
Вебторт рекомендует! 😉