Файлы с расширением «.CSV» — верные хранители табличных данных, ставшие популярными не случайно: с ними довольно просто работать, кроме того, большинство программ для обработки табличных данных могут использовать формат «.CSV». А в любимом для большинства специалистов по Data Science языке Python, существует целая библиотека, упрощающая работу с табличными данными. Имя этой библиотеки Pandas! Реализуем чтение csv файла в Python при помощи Pandas на примере ниже. Но прежде..
— Краткий ликбез для тех, кто спешит —
Открываем файл .csv в Python при помощи Pandas
# Импортируем Pandas
import pandas as pd
# Считываем содержимое файла в переменную data:
data = pd.read_csv("Здесь укажите путь к файлу .csv")
# Проверяем, что данные прочитаны:
data.head(5)
Если Вы желаете вывести данные без наименований столбцов, или же с другими особыми пожеланиями, переходите к разделу этой статьи «Настраиваем аргументы функции read_csv()».
А теперь обо всем с подробностями на примере!
Если после ликбеза у Вас остались вопросы, предлагаю подробно рассмотреть процесс открытия csv файла на примере базы данных проектов из Kikstarter-a. Увлеченный пользователь сайта Kaggle собрал информацию о размещенных на Kikstarter-е проектах, включающую в себя название проекта, необходимую сумму, успешность проекта и т. д. Предлагаю взглянуть на эту базу данных при помощи Python. Для начала скачаем файл с данными за 2018 год. Сделать это можно по ссылке https://www.kaggle.com/kemical/kickstarter-projects. На фото ниже показано, где нужно нажать для осуществления загрузки. Необходимый для загрузки файл называется «ks-projects-201801.csv»:

Файл загружен! Переходим к написанию кода. Кстати, работать будем как настоящие профессионалы по четкому плану:
- Определим путь к файлу
- Импортируем Pandas
- Загрузим данные из csv файла в переменную data
- Выведем часть данных на экран, чтобы убедиться в том, что файл был успешно прочитан
- Реализуем самые смелые пожелания в рамках вида прочитанных данных (удалим названия колонок, оставим названия колонок и т.д.)
Итак, следуя плану, приступим к реализации первого пункта:
1. Определим путь к файлу
После загрузки файла на компьютер, необходимо определить путь к этому файлу. Предлагаю воспользоваться универсальным способом и указать путь к файлу относительно рабочей директории. Кстати, давайте уточним путь к Вашей рабочей директории! Для этого исполним код:
# подключаем модуль pathlib и библиотеку Path модуля pathlib
# если pathlib не установлен, сделать это можно
# с помощью команды pip install pathlib
import pathlib
from pathlib import Path
#Получаем строку, содержащую путь к рабочей директории:
work_path = pathlib.Path.cwd()
Теперь путь к рабочей директории находится в переменной work_path. Поэтому вывести на экран адрес рабочего каталога, в котором по умолчанию хранятся скрипты, можно при помощи строки:
print(work_path)
Предлагаю создать в рабочей директории папку «datasets» и загрузить в нее .csv файл со скачанными данными (предварительно распакуйте скачанный архив так, чтобы файл 'ks-projects-201801.csv'находился непосредственно в папке «datasets»). В этом случае путь к .csv файлу будет выглядеть так:
# подключаем модуль pathlib и библиотеку Path модуля pathlib
import pathlib
from pathlib import Path
#Получаем строку, содержащую путь к рабочей директории:
work_path = pathlib.Path.cwd()
# сохраним путь к csv файлу в переменной data_path
data_path = Path(work_path, 'datasets', 'ks-projects-201801.csv')
2. Импортируем Pandas
1. Прежде всего, импортируем библиотеку Pandas в проект. Сделать это можно, добавив строку «import pandas as pd» в начале скрипта:
# Подключаем библиотеку Pandas
import pandas as pd
# подключаем модуль pathlib и библиотеку Path модуля pathlib
import pathlib
from pathlib import Path
#Получаем строку, содержащую путь к рабочей директории:
work_path = pathlib.Path.cwd()
# сохраним путь к csv файлу в переменной data_path
data_path = Path(work_path, 'datasets', 'ks-projects-201801.csv')
Теперь обращаться к функциям из Pandas будем, предваряя название функции префиксом «pd.».
3. Загрузим данные из csv-файла в переменную data
Для того, чтобы осуществить чтение csv файла в Python, вызовем функцию read_csv() из библиотеки Pandas и передадим в качестве аргумента адрес, по которому располагается csv файл:
# Подключаем библиотеку Pandas
import pandas as pd
# подключаем модуль pathlib и библиотеку Path модуля pathlib
import pathlib
from pathlib import Path
#Получаем строку, содержащую путь к рабочей директории:
work_path = pathlib.Path.cwd()
# сохраним путь к csv файлу в переменной data_path
data_path = Path(work_path, 'datasets', 'ks-projects-201801.csv')
# Загружаем данные из csv файла в переменную data
data = pd.read_csv(data_path)
После прочтения csv файла в Python все содержимое файла хранится в переменной data. Предлагаю убедиться в том, что файл был успешно прочитан и вывести данные на экран.
4. Вывод данных из прочитанного csv файла в Python
Предлагаю вывести 10 первых строк на экран. Для этого вызовем функцию head() и передадим ей в качестве аргументов желаемое для вывода число строк:
# Подключаем библиотеку Pandas
import pandas as pd
# подключаем модуль pathlib и библиотеку Path модуля pathlib
import pathlib
from pathlib import Path
#Получаем строку, содержащую путь к рабочей директории:
work_path = pathlib.Path.cwd()
# сохраним путь к csv файлу в переменной data_path
data_path = Path(work_path, 'datasets', 'ks-projects-201801.csv')
# Загружаем данные из csv файла в переменную data
data = pd.read_csv(data_path)
# Выведем первые 10 строк из прочитанного файла на экран
data.head(10)
Взгляните на результат работы функции head(10):
")
Кстати, если стройные ряды строк или столбцов в выводе нарушило многоточие (как на изображении ниже), исправить это поможет статья Как вывести всю таблицу в Pandas .
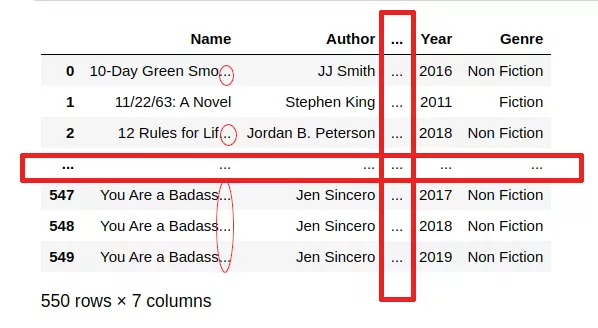
Давайте рассмотрим выведенную таблицу. По умолчанию, строки пронумерованы, каждый столбец таблицы имеет заголовок. Установив значения аргументов функции read_csv() желаемым образом, вы можете прочитать csv-файл без заголовков, пропустить некоторые строки, а также определить вид разделителя. Давайте рассмотрим, как это сделать.
 Фанаты BIG DATЫ — наш Телеграм-канал для всех увлеченных изучением Python, Data Science, ML, нейросетями и т.д. Присоединяйтесь, вместе веселее! 😉
Фанаты BIG DATЫ — наш Телеграм-канал для всех увлеченных изучением Python, Data Science, ML, нейросетями и т.д. Присоединяйтесь, вместе веселее! 😉
5. Настраиваем аргументы функции read_csv()
Рассмотрим некоторые из аргументов функции read_csv(), которые могут Вам помочь в работе:
1) Работаем с именами столбцов:
Параметр header содержит номер строки, в которой прописаны имена столбцов. Обычно это нулевая строка, и по-умолчанию параметр header имеет нулевое значение, т. е. header=0.
Строка: data = pd.read_csv(data_path, header=0) равносильна строке: data = pd.read_csv(data_path)
Давайте изменим значение header на header=2. В итоге вторая строка станет заголовком, и далее файл будет прочитан начиная с 3-й строки (т.е. 3-я строка сместится на нулевую позицию). Для сравнения рассмотрим, как выглядит одна и та же таблица при header=0 и header=2:


Иногда бывает так, что в исходном файле отсутствуют названия столбцов. В данном случае, чтобы строка с информативными данными не превратилась в заголовки столбцов, нужно определить значение header как None:
data = pd.read_csv(data_path, header=None)
У рассматриваемой выше таблицы, нулевая строка содержит заголовки столбцов, поэтому значение header=None только «спутает всю малину»:

2) Читаем только часть файла:
Аргумент nrows позволяет считать заданное количество строк. Например, если nnows=3, то функция read_csv() прочитает только 3 строки:
data = pd.read_csv(data_path, nrows=3)
data

Аргумент sciprows позволяет пропустить указанное количество строк при чтении. Например:
- Если skiprows = 5, чтение файла начнется с 5 строки, при этом имена колонок, если не указано другое, также будут прочитаны.
- Если skiprows = [3, 5, 8], то строки под номерами 3, 5, 8 не будут прочитаны,
- При skiprows = range(4, 7) из чтения будут исключены строки 4,5,6.
3) Устанавливаем вид разделителя:
Чтобы задать вид разделителя, нужно в функции read_csv() определить аргумент sep. Например, требуется прочитать файл вида:

В представленном выше файле данные разделены символом «|». Поэтому, для прочтения этого файла в функции read_csv нужно определить аргумент sep = «|»:
data = pd.read_csv(data_path, sep="|")
Мы рассмотрели только некоторые возможные аргументы функции read_csv(), которая используется для csv файла в Python. С полным списком аргументов можно ознакомиться в официальной документации.
спасибо очень помогло, импорт немного смутил
import pathlib
from pathlib import Path
Path можно было вызвать pathlib.Path()