Что такое номинальные порядковые признаки?
Номинальные порядковые признаки — это признаки, представленные упорядоченными категориями. Например, оценка за урок может быть в виде номинальных значений: ‘отлично’, ‘хорошо’, ‘удовлетворительно’, ‘неудовлетворительно’. Если кот Матроскин получил за урок оценку ‘удовлетворительно’, а его друг Шарик — ‘отлично’, мы можем сделать вывод, что у Шарика оценка лучше, однако, это не значит, что Шарик на 2/5 или 3/4 лучше подготовился к уроку. То есть исходя из порядковых данных нельзя судить о количественных пропорциях в знаниях учеников, но можно говорить о том, что различия есть.
Другие примеры номинальных порядковых признаков: военное звание, ученая степень, всевозможные рейтинги
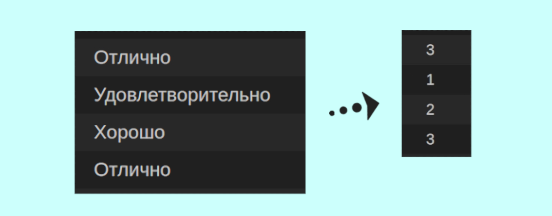
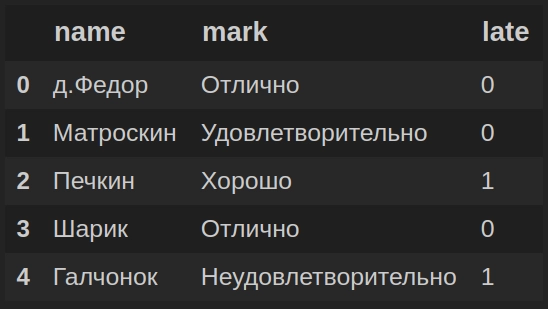
В рассмотренном выше примере система оценок была представлена номинальными значениями: ‘отлично’, ‘хорошо’, ‘удовлетворительно’, ‘неудовлетворительно’. Работать с такими данными не всегда удобно. Поэтому мы рассмотрим 2 способа перевода номинальных порядковых данных в числовые порядковые данные (‘неудовлетворительно’ переведем в значение 0, ‘удовлетворительно’ — в 1, ‘хорошо’ — в 2 и ‘отлично’ — в 3).
Создадим игрушечную таблицу с помощью кода:
import pandas as pd
df = pd.DataFrame({'name': ['д.Федор', 'Матроскин', 'Печкин',
'Шарик', 'Галчонок'],
'mark': ['Отлично', 'Удовлетворительно', 'Хорошо',
'Отлично', 'Неудовлетворительно'],
'late': [0, 0, 1, 0, 1]})
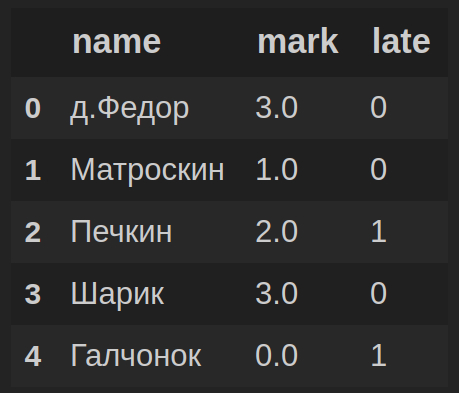
Созданный DataFrame df имеет вид:
Рассмотрим 2 способа преобразования номинальных порядковых значений колонки ‘mark’ в числовые порядковые значения:
Способ №1: преобразуем номинальные порядковые признаки в числовые с помощью метода map()
Сначала создадим словарь nums, ключами которого будут текущие значения столбца ‘mark’, а значениями — соответствующие ключам числа для замены:
nums = {'Неудовлетворительно': 0,
'Удовлетворительно': 1,
'Хорошо': 2, 'Отлично': 3}
Так как метод data.map(foo) применяет переданную ему в качестве аргумента функцию foo() ко всем элементам структуры data, то следующая конструкция позволит заменить текущие номинальные признаки в столбце ‘mark’ соответствующими им числовыми значениями из словаря nums:
data['mark'] = data['mark'].map(nums)
Полный код преобразования выглядит так:
import pandas as pd
data = pd.DataFrame({'name': ['д.Федор', 'Матроскин', 'Печкин', 'Шарик', 'Галчонок'],
'mark': ['Отлично', 'Удовлетворительно', 'Хорошо', 'Отлично', 'Неудовлетворительно'],
'late': [0, 0, 1, 0, 1]})
nums = {'Неудовлетворительно': 0,
'Удовлетворительно': 1,
'Хорошо': 2, 'Отлично': 3}
data['mark'] = data['mark'].map(nums)
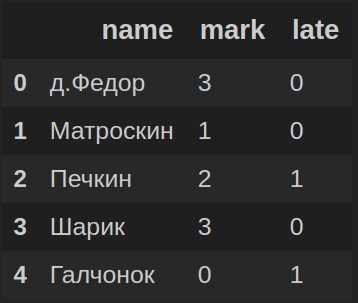
Полученный результат:
Способ №2: преобразуем номинальные порядковые признаки в числовые с помощью OrdinalEncoder
Прежде всего импортируем OrdinalEncoder из библиотеки scikit-learn, после чего создадим список с текстовыми версиями оценок, инициируем энкодер и преобразуем данные колонки mark в цифровые:
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
data = pd.DataFrame({'name': ['д.Федор', 'Матроскин', 'Печкин', 'Шарик', 'Галчонок'],
'mark': ['Отлично', 'Удовлетворительно', 'Хорошо', 'Отлично', 'Неудовлетворительно'],
'late': [0, 0, 1, 0, 1]})
# Создадим список с номинальными оценками:
marks = ['Неудовлетворительно', 'Удовлетворительно', 'Хорошо', 'Отлично']
# Создадим encoder:
enc = OrdinalEncoder(categories = [marks])
# Преобразуем значения столбца 'mark':
df['mark'] = enc.fit_transform(df[['mark']])
В результате получим таблицу с категориальными числовыми данными в столбце ‘mark’: