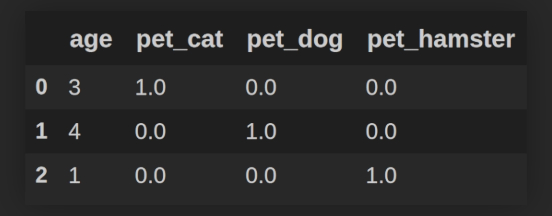
One Hot Encoding — способ преобразования категориальных данных в числовые. Основная идея One Hot Encoding заключается в том, что для каждой уникальной категории создается столбец, содержащий значения 0 или 1 в зависимости от того, характерна ли данная категория для текущей записи. Например, у нас есть игрушечная таблица df с информацией о домашних питомцах:

Обратите внимание, что в столбце pet представлены категориальные данные 3х видов: cat, dog, hamster Так как модели не работают со строковыми значениями, необходимо преобразовать содержимое столбца pet в числа. Но если мы вместо cat напишем 0, dog заменим на 1, а hamster на 2, то модель может решить, что хомяк (hamster) лучше кота (cat), ведь у него целых 2 балла, в противовес кошачьему нулю. Мало того, что это может привести к неверным результатам, так ещё и за котиков обидно ;-).
Поэтому будем придерживаться другой стратегии: для категории cat мы создадим новый столбец pet_cat со значениями: 1 — если для текущей записи df.pet == cat, 0 — если для текущей записи df.pet != cat Аналогично поступим для категорий dog и hamster:
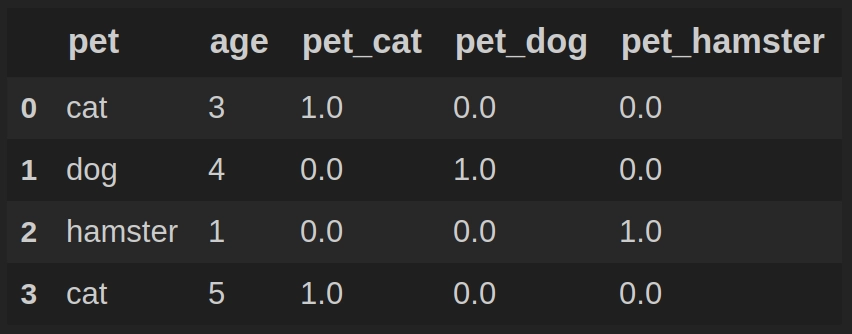
(перед обучением модели следует удалить столбец pet, как это сделать, рассмотрим ниже)
Как вы уже догадались, описанный выше способ называется One Hot Encoding, или горячим кодированием. Подобное преобразование можно осуществить в цикле Python, но мы воспользуемся готовым инструментом библиотеки sklearn под названием OneHotEncoder.
Реализуем One Hot Encoding с помощью sklearn
Реализуем горячее кодирование столбца pet рассмотренной выше таблицы df:
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
# Исходный DataFrame
pets = {'pet': ['cat', 'dog', 'hamster', 'cat'],
'age': [3, 4, 1, 5]}
df = pd.DataFrame(pets)
# Объявим енкодер
e = OneHotEncoder(sparse=False)
# Применим горячее кодирование к столбцу pet:
edf = e.fit_transform(df[['pet']])
# Сохраним результат в DataFrame edf:
edf = pd.DataFrame(edf)
# Добавим имена новым столбцам:
edf.columns = e.get_feature_names_out()
# Объединим df и edf:
df = df.join(edf)
# Удалим исходный столбец pet:
df.drop(columns='pet', inplace=True)
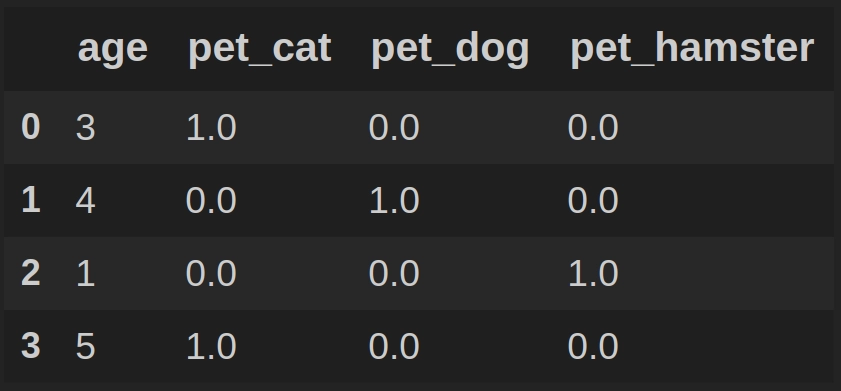
В результате получим DataFrame df:
 Фанаты BIG DATЫ — наш Телеграм-канал для всех увлеченных изучением Python, Data Science, ML, нейросетями и т.д. Присоединяйтесь, вместе веселее! 😉
Фанаты BIG DATЫ — наш Телеграм-канал для всех увлеченных изучением Python, Data Science, ML, нейросетями и т.д. Присоединяйтесь, вместе веселее! 😉