

Ничто так не пробуждает интерес к сравнению, как предварительная обработка данных! В тот самый момент, когда «подозреваемые в сходстве» данные тщательно отобраны и помещены в разные колонки (или столбцы), самое время воспользоваться рассмотренными ниже способом и сравнить столбцы в Pandas!
Сравниваем 2 числовых столбца в Pandas
В качестве примера «сфабрикуем» простейшую таблицу, состоящую из 10 строк и двух столбцов, подлежащих сравнению. Итак:
Исходные данные
Дано: таблица под названием df_nums с числовыми значениями в столбцах col1 и col2 следующего вида:

Создать такую таблицу в Pandas можно при помощи вызова конструктора класса DataFrame. Только не забудьте предварительно импортировать библиотеку Pandas:
import pandas as pd </br>df_nums = pd.DataFrame({'col1': [1,2,3,400,500], 'col2'[500,400,3,2,1]})Что нужно сделать?
1. Сравнить значения в столбце col1 со значениями в столбце col2 (для сравнения можно использовать знаки: « < » (меньше), « > » (больше), « == » (равно), « != » (не равно), « <= » (меньше или равно), « >= » (больше или равно)).
2. Получить результаты сравнения в виде boolean значений False или True
3. Записать результат сравнения в новый столбец «compared» таблицы df_nums
Закодим решение!
1. Прежде всего, для большей наглядности, выведем таблицу df_nums на экран:
# импортируем библиотеку pandas
import pandas as pd
# создаем дата-фрейм (или таблицу) df_nums
df_nums = pd.DataFrame({'col1': [1,2,3,400,500], 'col2': [500,400,3,2,1]})
# выводим таблицу на экран
df_nums.head()

2. Сравним столбцы в Pandas. Для этого составим простое неравенство, объектами которого будут являться столбцы col1 и col2 таблицы df_nums, а знаком сравнения может быть любой из перечисленных знаков:
- « < » (меньше)
- « <= » (меньше или равно)
- « > » (больше)
- « >= » (больше или равно)
- « == » (равно)
- « != » (не равно)
В качестве примера рассмотрим сравнение со знаком меньше « < ». Тогда неравенство будет иметь вид:
df_nums['col1'] < df_nums['col2']
Так как мы ожидаем получить результат сравнения, создадим столбец df_nums[‘compares’] и сразу же запишем результат сравнения во вновь созданный столбец:
# импортируем библиотеку pandas
import pandas as pd
# создаем дата-фрейм (или таблицу) df_nums
df_nums = pd.DataFrame({'col1': [1,2,3,400,500], 'col2': [500,400,3,2,1]})
# выводим таблицу на экран
df_nums.head()
# сравниваем col1 и col2 и записываем результат сравнения в compare
df_nums['compare'] = df_nums['col1'] < df_nums['col2']
В результате выполнения приведенного выше кода, таблица df_nums примет вид:

В обновленной таблице результат сравнения колонок col1 и col2 записан в столбце compared.
Описанный способ сравнения столбцов с числовыми значениями, можно изобразить схематически как:

Сравниваем столбцы со строковыми значениями
Чтобы сравнить строковые значения в столбцах таблицы, мы будем использовать принцип, приведенный на схеме выше. Однако, допустимые для сравнения знаки ограничим знаками:
- «равно ли», то есть «==»
- «не равно», то есть «!=»
Рассмотрим пример сравнения столбцов со строковыми значениями:
1. Создаем таблицу и выводим её на экран
В качестве примера создадим простейшую таблицу df_text с незатейливым содержанием:
import pandas as pd
# создаем таблицу df_text
df_text = pd.DataFrame({'col1': ['C', 'макарошками?', 'Нет!', 'C', 'пюрешкой!'], 'col2': ['C', 'макаронами?', 'Нет!', 'C', 'пюре-е-ешкой!']})
# Вывод таблицы на экран
df_text.head()
В итоге получим таблицу следующего вида:
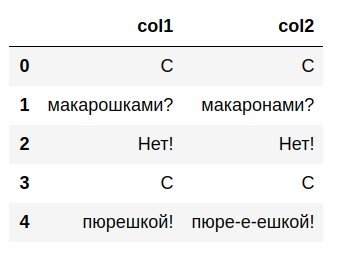
2. Сравниваем столбцы со строковыми значениями
Чтобы выяснить равны ли значения в столбцах col1 и col2, составим неравенство: df_text[‘col1’] < df_text[‘col2’], а результат неравенства запишем в столбце ‘compare’ таблицы df_text:
import pandas as pd
df_text = pd.DataFrame({'col1': ['C', 'макарошками?', 'Нет!', 'C', 'пюрешкой!'], 'col2': ['C', 'макаронами?', 'Нет!', 'C', 'пюре-е-ешкой!']})
df_text.head()
# Сравниваем строки и записываем результат сравнения в новый столбец compare
df_text['compare'] = df_text['col1'] == df_text['col2']
#Выведем таблицу с результатом сравнения на экран
df_text.head()

Взгляните, мы получили результат булева типа. В случае, если для текущей строки неравенство верно, то результат сравнения — True, в противном случае — False. Если мы поменяем в неравенстве знак «==» на знак «!=», то получим обратный результат, как в столбце ‘compare !=’ на изображении ниже:

Похоже, Python отлично справляется со сравнением строковых значений в столбцах, используя интуитивно понятную схему сравнения двух элементов:

Заключительный бонус
А в заключение хотелось бы добавить бонус: раз уж мы взялись сравнивать столбцы таблицы df_text, то предлагаю вывести на экран строки с отличными значениями в столбцах col1 и col2. Используя приведенный выше код, сделать это довольно просто: нужно вывести строки со значением False в столбце compare:
5import pandas as pd
df_text = pd.DataFrame({'col1': ['C', 'макарошками?', 'Нет!', 'C', 'пюрешкой!'], 'col2': ['C', 'макаронами?', 'Нет!', 'C', 'пюре-е-ешкой!']})
df_text.head()
# Сравниваем строки и записываем результат сравнения в новый столбец compare
df_text['compare'] = df_text['col1'] == df_text['col2']
# запишем в different_text все строки со значением false в столбце „compare“
different_text = df_text[df_text['compare'] == False]
# выведем строки с разными значениями в столбцах col1 и col2 на экран
different_text.head()
