Давайте представим, что у вас есть файл с текстовыми сообщениями и вам нужно предсказать, какие из них являются спамом, а какие — нет. Вы нацелены построить модель, обучить её на размеченных данных и выдать блестящий результат! И тут возникает первый вопрос: как скормить текст нашей модели? Ведь рацион data science моделей обычно ограничен векторами, матрицами и тензорами, а мы тут со своими текстовыми сообщениями.. Но ведь даже из обычной картошки можно приготовить вкусные чипсы, если знать рецепт приготовления! Что уж говорить о цифровой информации — используя секреты предварительной обработки текста, можно легко перевести обработанный текст в векторы с нулями и единицами! Именно такой предварительной обработкой текста «до нужной кондиции» является препроцессинг текста в Python. В настоящее время повара data science используют следующие приемы для предварительной обработки текста:
- cleaning — очистка данных
- tokenization — токенизация
- stop-words removal — удаление стоп-слов
- stemming and lemmatization — стемминг и лемматизация
Мы рассмотрим каждый из перечисленных приемов на примере препроцессинга сообщений на английском языке, часть из которых является спамом. Скачать файл с сообщениями можно по ссылке: https://www.kaggle.com/team-ai/spam-text-message-classification, либо с моего сайта по ссылке: «SPAM text message 20170820 — Data.csv». Для того, чтобы этапы препроцессинга текстовых данных стали проще для восприятия, сравним их с последовательной обработкой картофеля обыкновенного до состояния почти-чипсов. Однако, прежде взглянем на фронт работы: откроем csv-файл в редакторе. Для этого создадим новый питоновский файл и исполним следующий код:
import pandas as pd
# Сбрасываем ограничения на количество выводимых рядов
pd.set_option('display.max_rows', None)
# Сбрасываем ограничения на число столбцов
pd.set_option('display.max_columns', None)
# Сбрасываем ограничения на количество символов в записи
pd.set_option('display.max_colwidth', None)
# считываем данные из csv-файла в переменную data
data = pd.read_csv('SPAM text message 20170820 - Data.csv')
# выводим первые 10 строк
data.head(10)
Взглянем на результат:
Мы видим, что файл загружен, в поле «Message» действительно располагаются текстовые сообщения, все идет по плану, а это значит, что можно приступать к препроцессингу текста! И первым этапом будет cleaning!
1. Cleaning — очистка данных
Наши данные, как и картофель, нуждаются в очищении от мусора и несъедобной кожуры. В текстовых данных «несъедобной кожурой» являются различные символы препинания, скобки, кавычки и прочие слеши и звездочки. По большей части, они не несут смысловой нагрузки, зато способны нагрузить машину— ведь каждый такой символ нужно перевести в числовой код, сохранить, затем потратить ресурсы на его обработку и т. д. Нет уж, лучше сразу избавимся от этой «шелухи»! Закодим функцию clean_text_data() и почистим с ее помощью наши данные!
import pandas as pd
import re
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
data = pd.read_csv('SPAM text message 20170820 - Data.csv')
data.head(10)
# Функция для очистки текста от лишних символов
def clean_text(text):
# приводим текст к нижнему регистру
text = text.lower()
# создаем регулярное выражение для удаления лишних символов
regular = r'[\*+\#+\№\"\-+\+\=+\?+\&\^\.+\;\,+\>+\(\)\/+\:\\+]'
# регулярное выражение для замены ссылки на "URL"
regular_url = r'(http\S+)|(www\S+)|([\w\d]+www\S+)|([\w\d]+http\S+)'
# удаляем лишние символы
text = re.sub(regular, '', text)
# заменяем ссылки на "URL"
text = re.sub(regular_url, r'URL', text)
# заменяем числа и цифры на ' NUM '
text = re.sub(r'(\d+\s\d+)|(\d+)',' NUM ', text)
# удаляем лишние пробелы
text = re.sub(r'\s+', ' ', text)
# возвращаем очищенные данные
return text
# создаем список для хранения очищенных данных
cleaned_text = []
# для каждого сообщения text из столбца data['Message']
for text in data['Message']:
# очищаем данные
text = clean_text(text)
# добавляем очищенные данные в список cleaned_text
cleaned_text.append(text)
# записываем очищенные данные в новую колонку 'Cleaned_msg'
data['Cleaned_msg'] = cleaned_text
Представленная выше функция приводит все данные к нижнему регистру, затем заменяет «неугодные» нам символы на пробелы. После этого производит замену ссылок на «URL», а чисел — на « NUM ». Завершающим этапом очистки становится удаление лишних пробелов. Конечно же, для каждого датасета очищение текста будет производиться в соответствии с поставленной задачей. Например, если требуется определить тему текста, то факт наличия ссылок не играет существенной роли, поэтому ссылки можно удалить. В нашем же случае, наличие ссылок в сообщении, как и восклицательных знаков, являются важными маяками спам-сообщений, а вот адрес, на который они указывают — не важен, поэтому все ссылки мы заменяем на «URL». После того, как функция готова, мы вызываем ее в цикле for для данных из колонки data[‘Message’] и записываем полученный результат в новый столбец под названием ‘Cleaned_msg’.
Давайте выведем на экран строку под номером «273» из таблицы data и сравним старые данные из столбца «Message» с очищенными данными, сохраненными в столбце «Cleaned_msg»:
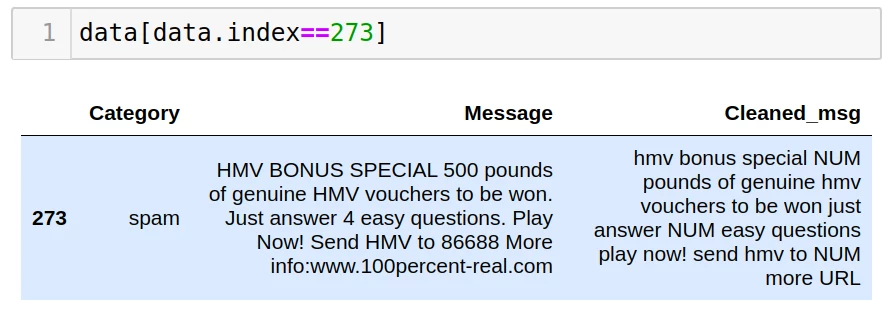
Отлично! Регистр символов изменен на нижний, лишние символы удалены, ссылки и числа заменены символами «URL» и « NUM » соответственно. Теперь можно переходить к следующему этапу!
2. Tokenization — токенизация
import pandas as pd
import re
# импортируем библиотеку nltk
import nltk
# Импортируем метод word_tokenize из библиотеки nltk
from nltk.tokenize import word_tokenize
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
data = pd.read_csv('SPAM text message 20170820 - Data.csv')
data.head(10)
# Функция для очистки текста
def clean_text(text):
text = text.lower()
regular = r'[\*+\#+\№\"\-+\+\=+\?+\&\^\.+\;\,+\>+\(\)\/+\:\\+]'
regular_url = r'(http\S+)|(www\S+)|([\w\d]+www\S+)|([\w\d]+http\S+)'
text = re.sub(regular, '', text)
text = re.sub(regular_url, r'URL', text)
text = re.sub(r'(\d+\s\d+)|(\d+)',' NUM ', text)
text = re.sub(r'\s+', ' ', text)
return text
cleaned_text = []
# создаем список для хранения токенов
tokens = []
# для каждого сообщения text из столбца data['Message']
for text in data['Message']:
# очищаем данные и сохраняем результат в списке cleaned_text
text = clean_text(text)
cleaned_text.append(text)
#разбиваем текст на токены с сохраняем результат в списке tokens
text = word_tokenize(text)
tokens.append(text)
data['Cleaned_msg'] = cleaned_text
# Сохраняем разбитые на токены сообщения в новой колонке 'Tokens_msg'
data['Tokens_msg'] = tokens
Более подробно процесс токенизации текста с помощью библиотеки nltk рассматривается в статье: «Токенизация слов при помощи nltk и keras»
Предлагаю взглянуть на результат токенизации сообщения под номером 273:
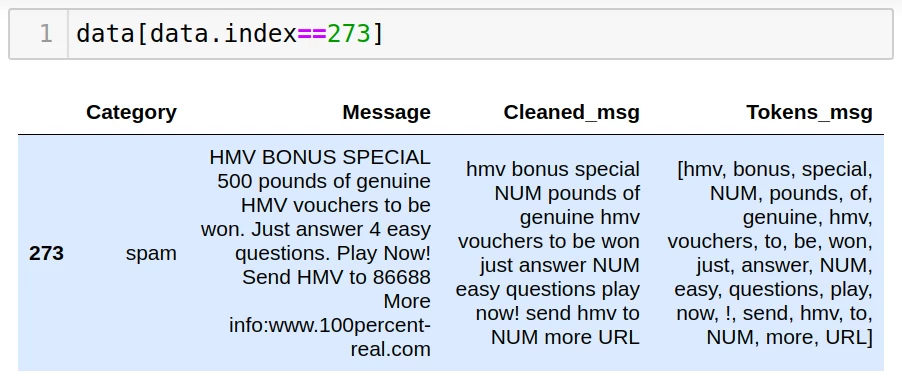
Мы видим, что в таблице data появился столбец «Tokens_msg» со списком всех слов, включенных в сообщение. Как думаете, все ли слова в 273 сообщении влияют на результат, или часть из них можно удалить? Наверняка вы догадались, что этот вопрос не случаен, и мы плавно приближаемся к следующему этапу препроцессинга текста — удалению стоп-слов или stop-words removal.
Удаление стоп-слов (stop-words removal)
Вернемся к нашему картофельному блюду: предположим, что мы готовим не просто чипсы, а идеальные чипсы круглой формы с диаметром 7 см. Однако, среди нарезанных нами кусочков то и дело показываются мелкие элементы. Эти мелкие кусочки совершенно не годятся на роль будущих чипсов и только засоряют обзор. Поэтому их нужно непременно убрать с рабочей зоны. Аналогичным образом мы поступим и со словами в тексте сообщений. Преимущественно короткие слова, которые чаще остальных встречаются в речи и не влияют на смысловой оттенок фраз, можно удалять, не опасаясь за искажение результата. Такие слова называются стоп-словами.
В качестве примера стоп-слов в русском языке можно привести союзы (и, или, а, но и др.), местоимения (я, ты, он, она и др.), междометия (ох, ой, ага, эх.. ) и так далее. В английском языке это: ‘i’, ‘me’, ‘my’, ‘myself’, ‘we’, ‘our’, ‘ours’, ‘ourselves’, ‘you’, «you’re», «you’ve», «you’ll», «you’d», ‘your’, ‘yours’, ‘yourself’ и т.д.
Ну что, согласны «откромсать» стоп-слова прямо сейчас? Тогда нам необходимо импортировать метод stopwords из библиотеки nltk, загрузить стоп-слова для английского языка и в цикле проверить каждое слово из текущего сообщения на вхождение в список стоп-слов. Ниже представлен наш код, дополненный строками, необходимыми для удаления стоп-слов:
import pandas as pd
import re
import nltk
from nltk.tokenize import word_tokenize
# Импортируем метод stopwords из библиотеки nltk
from nltk.corpus import stopwords
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
data = pd.read_csv('SPAM text message 20170820 - Data.csv')
data.head(10)
# Функция для очистки текста
def clean_text(text):
text = text.lower()
regular = r'[\*+\#+\№\"\-+\+\=+\?+\&\^\.+\;\,+\>+\(\)\/+\:\\+]'
regular_url = r'(http\S+)|(www\S+)|([\w\d]+www\S+)|([\w\d]+http\S+)'
text = re.sub(regular, '', text)
text = re.sub(regular_url, r'URL', text)
text = re.sub(r'(\d+\s\d+)|(\d+)',' NUM ', text)
text = re.sub(r'\s+', ' ', text)
return text
cleaned_text = []
tokens = []
# загружаем список с английскими стоп-словами в переменную stop-words
stop_words = stopwords.words('english')
# создаем список для хранения данных без стоп-слов
stopwords_cleaned = []
# для каждого сообщения text из столбца data['Message']
for text in data['Message']:
# cleaning
text = clean_text(text)
cleaned_text.append(text)
# tokenization
text = word_tokenize(text)
tokens.append(text)
# с помощью цикла for поочередно проверяем каждое слово(токен) текущего сообщения
# на вхождение в список стоп-слов. Если токен не является стоп-словом,
# то добавляем его в список stopwords_cleaned
text = [word for word in text if word not in stop_words]
stopwords_cleaned.append(text)
data['Cleaned_msg'] = cleaned_text
data['Tokens_msg'] = tokens
# Сохраняем сообщения без стоп-слов в новой колонке 'noStopwords_msg'
data['noStopwords_msg'] = stopwords_cleaned
Проверим, как изменилось сообщение с идентификатором 273 после удаления стоп-слов:

Сравним содержимое столбца Tokens_msg со столбцом noStopwords_msg: очевидно, что словесный груз в последнем столбце стал легче за счет таких удаленных слов, как of, to, be, just, now, more.. А это значит, что процесс удаления стоп-слов прошёл успешно!
Кстати, а знаете ли вы, как дополнить загруженный список стоп-слов новыми словами или, напротив, удалить некоторые из них? Рассказываю подробнее:
## --- Пример манипуляций со списком стоп-слов ---
import nltk
from nltk.corpus import stopwords
# загружаем список с английскими стоп-словами в переменную stop-words
stop_words = stopwords.words('english')
# выведем список стоп-слов на экран
print(stop_words)
# добавим слово krendel в список стоп-слов
stop_words.append('krendel')
# удалим слово just из списка стоп-слова
stop_words.remove('just')
Стемминг или лемматизация
Вернемся к нашим чипсам: картофель почищен и порезан, лишние фрагменты удалены, осталось лишь подровнять края до идеальной формы, и мы получим превосходно отформованный материал! Возможно, в кулинарии такой фанатизм излишен, но когда дело касается ресурсов компьютера, сомневаться не приходится! Ведь если мы приведем каждое слово к его начальной форме, то сэкономим ресурсы нашей машины, сохранив смысловой посыл сообщения. Однако, давайте определимся, что такое начальная форма слова? Возьмем, к примеру, слово «playing»: отсекаем «ing», получаем начальную форму — «play». А для слова «cats»? Отсекаем окончание «s», получаем «cat». Все просто! Такой метод отсечения суффиксов, окончаний и приставок с целью приблизить слово к его начальной форме получил название stemming. Однако, этот метод не идеален: ниже я приведу пример стемминга фразы «ladies and gentlemen» и полученный результат:
## --- пример стемминга фразы «ladies and gentlemen» ---
import nltk
from nltk.tokenize import word_tokenize
# импортируем стеммер
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
text = "ladies and gentlemen"
tokens = nltk.word_tokenize(text)
for word in tokens:
# преобразуем каждое слово с помощью стемминга
print(porter_stemmer.stem(word))

Похоже, это бездумное отсечение суффиксов и окончаний, не всегда работает верно, хотя обходит конкурента по скорости и занимаемым ресурсам. А конкурент носит гордое имя «лемматизация» (или lemmatization). Этот метод опирается на морфологический анализ слова, поэтому результат максимально приближен к реальному. Раз уж мы рассмотрели пример стемминга для фразы «ladies and gentlemen», то для сравнения получим результат лемматизации этой же фразы, а затем вернемся к нашему датасету:
## --- пример лемматизации фразы «ladies and gentlemen» ---
import nltk
from nltk.tokenize import word_tokenize
# импортируем лемматайзер
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
text = "ladies and gentlemen"
tokens = nltk.word_tokenize(text)
for word in tokens:
# преобразуем каждое слово с помощью лемматайзера
print(lemmatizer.lemmatize(word))

В результате лемматизации мы получили верные начальные формы слов ladies и gentlemen, чего не смогли добиться стеммингом. Поэтому при наличии ресурсов, лемматизация является наиболее разумным выбором для построения моделей. Для преобразования текста из нашего датасета data, мы также будем использовать лемматизацию. Для этого мы импортируем lemmatizer под названием WordNetLemmatizer() и с помощью функции lemmatize() получим основные формы слов в сообщениях:
import pandas as pd
import re
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
# Импортируем лемматизатор из библиотеки nltk
from nltk.stem import WordNetLemmatizer
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
data = pd.read_csv('SPAM text message 20170820 - Data.csv')
data.head(10)
# Функция для очистки текста
def clean_text(text):
text = text.lower()
regular = r'[\*+\#+\№\"\-+\+\=+\?+\&\^\.+\;\,+\>+\(\)\/+\:\\+]'
regular_url = r'(http\S+)|(www\S+)|([\w\d]+www\S+)|([\w\d]+http\S+)'
text = re.sub(regular, '', text)
text = re.sub(regular_url, r'URL', text)
text = re.sub(r'(\d+\s\d+)|(\d+)',' NUM ', text)
text = re.sub(r'\s+', ' ', text)
return text
cleaned_text = []
tokens = []
stop_words = stopwords.words('english')
stopwords_cleaned = []
# инициализируем лемматайзер
lemmatizer = WordNetLemmatizer()
# создаем список для хранения основных форм слов lemmas
lemmas = []
# для каждого сообщения text из столбца data['Message']
for text in data['Message']:
# cleaning
text = clean_text(text)
cleaned_text.append(text)
# tokenization
text = word_tokenize(text)
tokens.append(text)
# удаление стоп-слов
text = [word for word in text if word not in stop_words]
stopwords_cleaned.append(text)
# для каждого слова из текущего сообщения вызываем функцию лемматизации
# и добавляем полученные леммы в список lemmas
text = [lemmatizer.lemmatize(word) for word in text]
lemmas.append(text)
data['Cleaned_msg'] = cleaned_text
data['Tokens_msg'] = tokens
data['noStopwords_msg'] = stopwords_cleaned
# Сохраняем основные формы слов сообщений в новой колонке 'Lemmas_msg'
data['Lemmas_msg'] = lemmas
Судя по результату, лемматайзер справился с задачей! А это значит, что мы рассмотрели заключительный этап препроцессинга текста и плавно подошли к подведению итогов!
Финальный код для препроцессинга текста
Хотелось бы обратить внимание, что на протяжении всей статьи мы дополняли датасет новыми колонками после каждого этапа препроцессинга текста. Это было нужно для демонстрации результата. На практике же нет необходимости в таком количестве дополнительных колонок. Поэтому в финале я предлагаю для рассмотрения код со всеми этапами препроцессинга, но без включения промежуточных результатов в датасет:
import pandas as pd
import re
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# снимаем ограничения в pandas на количество выводимых рядов и колонок,
# а также на ширину колонок
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
# загружаем датесет
data = pd.read_csv('SPAM text message 20170820 - Data.csv')
# Функция для очистки текста
def clean_text(text):
# приводим текст к нижнему регистру
text = text.lower()
# создаем регулярное выражение для удаления лишних символов
regular = r'[\*+\#+\№\"\-+\+\=+\?+\&\^\.+\;\,+\>+\(\)\/+\:\\+]'
# регулярное выражение для замены ссылки на "URL"
regular_url = r'(http\S+)|(www\S+)|([\w\d]+www\S+)|([\w\d]+http\S+)'
# удаляем лишние символы
text = re.sub(regular, '', text)
# заменяем ссылки на "URL"
text = re.sub(regular_url, r'URL', text)
# заменяем числа и цифры на ' NUM '
text = re.sub(r'(\d+\s\d+)|(\d+)',' NUM ', text)
# удаляем лишние пробелы
text = re.sub(r'\s+', ' ', text)
# возвращаем очищенные данные
return text
# создаем список для хранения преобразованных данных
processed_text = []
# загружаем стоп-слова для английского языка
stop_words = stopwords.words('english')
# инициализируем лемматайзер
lemmatizer = WordNetLemmatizer()
# для каждого сообщения text из столбца data['Message']
for text in data['Message']:
# cleaning
text = clean_text(text)
# tokenization
text = word_tokenize(text)
# удаление стоп-слов
text = [word for word in text if word not in stop_words]
# лемматизация
text = [lemmatizer.lemmatize(w) for w in text]
# добавляем преобразованный текст в список processed_text
processed_text.append(text)
# Сохраняем результат преобразования в новой колонке 'Processed_msg'
data['Processed_msg'] = processed_text
Выведем результат для строк 32-34:
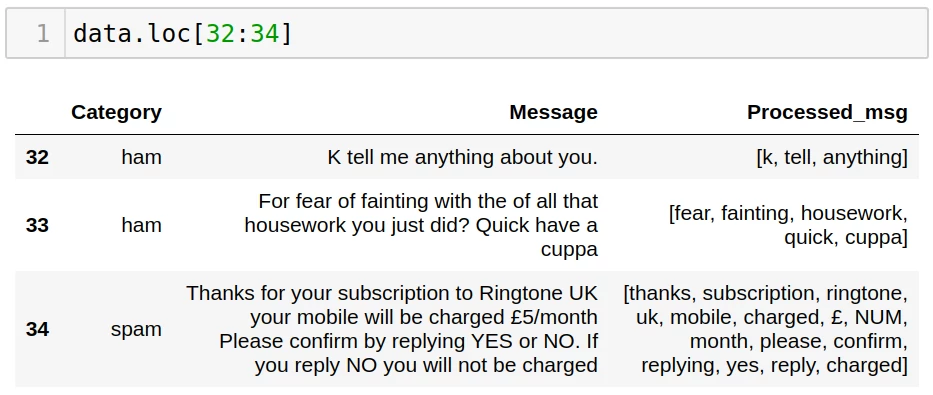
Препроцессинг текста в Python — подводим итоги
Думаю, что после проделанной работы у нас получатся отличные чипсы! Ведь мы выполнили большое число задач: cleaning, tokenization, stop-words removal, lemmatization и даже, как именитые шеф-повара, научились называть простые операции красивыми иностранными словами. Осталось лишь поджарить картофель, вернее — преобразовать полученные списки слов в векторы, но это уже тема для другой статьи!