
Решение задачи MNIST в Keras может послужить отличной стартовой площадкой в практике построения нейронных сетей для распознавания образов! В чем же заключается условие задачи MNIST, и какие данные для ее решения мы будем использовать?
Исходные данные
В принадлежащей Keras базе данных хранится датасет с фотографиями рукописных цифр от 0 до 9. Фотографии имеют следующий вид:

Размер каждой фотографии составляет 28×28 пикселей. Для каждой фотографии имеется соответствующая ей метка со значением изображенной цифры. Например, для расположенного ниже фото, соответствующая метка равна 2:

Что нужно сделать?
Построить модель и натренировать ее на большей части данных с цифрами так, чтобы можно было передавать модели фотографии с цифрами размером 28×28 пикселей и получать на выходе значение этой цифры.
Решение задачи MNIST в Keras
1. Импортируем необходимые модули и библиотеки:
Для решения задачи нам понадобятся:
- Tensorflow и Keras
- Библиотека matplotlib для вывода изображений с цифрами на экран.
- Объекты модели, слоев, оптимайзера для построения нейросети.
Подключим эти модули и библиотеки с помощью следующего кода:
import tensorflow as tf
import tensorflow.keras
# библиотека для вывода изображений
import matplotlib.pyplot as plt
%matplotlib inline
# -- Импорт для построения модели: --
# импорт слоев
from tensorflow.keras import layers
from tensorflow.keras.layers import Dense, Flatten
# импорт модели
from tensorflow.keras.models import Sequential
# импорт оптимайзера
from tensorflow.keras.optimizers import Adam
2. Загрузим датасет:
Прежде всего, импортируем данные MNIST из базы Keras:
# Импортируем набор данных MNIST
from tensorflow.keras.datasets import mnist
Данные, расположенные в базе данных Keras, обычно уже разделены на тренировочные и тестовые данные. На тренировочных данных мы будем обучать модель, а тестовые данные нам пригодятся для проверки качества работы модели. Для загрузки тренировочных и тестовых данных MNIST, воспользуемся функцией mnist.load_data():
# загружаем тренировочные и тестовые данные
(X_train, y_train), (X_test, y_test) = mnist.load_data()
В X_train мы считали изображения для тренировки, в y_train — метки тренировочных данных. В X_test и y_test, соответственно, изображения и метки тестовых данных.
Подробнее о загрузке датасета MNIST можно узнать из документации Tensorflow по ссылке: https://www.tensorflow.org/api_docs/python/tf/keras/datasets/mnist/load_data
3. Исследуем данные
- Узнаем длины массивов с данными
Для начала проверим, соответствует ли число изображений в массивах X_train и X_test количеству меток в массивах y_train и y_test соответственно:
# Узнаем длины полученных массивов
print(len(X_train), len(y_train), len(X_test), len(y_train))
Результат работы кода: 60000, 60000, 10000, 60000
Из выведенных на экран данных видно, что в массиве X_train содержится 60000 изображений, ровно столько же содержится и в массиве y_train с соответствующими метками. Тестовые данные X_test и y_test содержат по 10000 элементов.
- Исследуем первый элемент массива с изображениями X_train[0] и соответствующую ему метку y_train[0]
При работе с базой данных Keras можно быть уверенными в том, что все изображения имеют одинаковый размер и тип данных. Выведем эти параметры на экран на примере первого элемента в X_train:
# Проверка типа и размера данных
print(X_train[0].shape,X_train[0].dtype)
Результат на экране: (28, 28) uint8
Проверим, что из себя представляет первый элемент массива X_train[0]:
# Выведем первый элемент массива на экран
print(X_train[0])
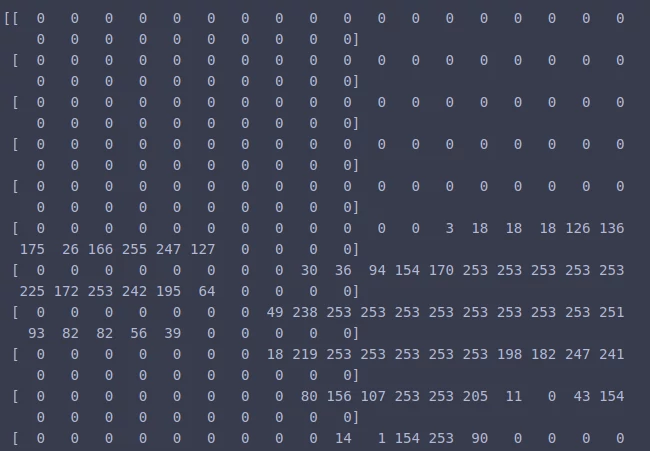
Каждый элемент массива X_train — это изображение, представленное в виде матрицы с числами от 0 до 255. Так как рассматриваемые изображения с цифрами черно-белые, то каждый пиксель этих изображений можно представить в виде числа от 0 до 255 в зависимости от интенсивности окрашивания этого пикселя.
А теперь узнаем, что содержится в y_train[0]:
print(y_train[0])
Результат на экране: 5
Это значит, что матрица X_train[0] представляет собой изображение с написанной цифрой 5. Давайте с помощью matplotlib выведем на экран изображение, соответствующее матрице X_train[0]:
# Выведем на экран хранящееся в X_train[0] изображение
plt.imshow(X_train[0], cmap='binary')
plt.axis('off')
В результате получим:
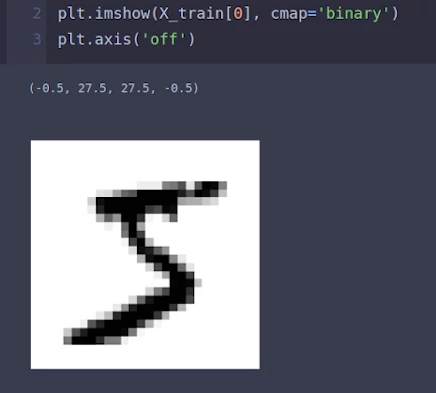
Действительно, на первом изображении трейнового датасета X_train[0] изображена цифра 5!
4. Преобразуем данные!
Так как изображения из базы данных Keras уже очищены, имеют одинаковые тип и размер, то этап преобразования данных не займет много времени. Все что нам нужно сделать, это преобразовать матрицы изображений (X_train, X_test) и целевые значения(y_train, y_test) так, чтобы представленные в них числа менялись от 0 до 1 (сейчас они меняются от 0 до 255). Таким образом, мы приведем числовые значения во входных и целевых данных к единому формату. Для этого мы поделим тензоры X_train и X_test на 255 (то есть на максимальные значения в матрицах):
# Преобразование данных в матрицах изображений
# X_train.max() возвращает значение 255
X_train = X_train/X_train.max()
X_test = X_test/X_test.max()
А целевые значения будем преобразовывать методом «one-hot encoding». Что это значит? Это значит, что целевое значение y_train[0] = 5 будет преобразовано в вектор y_train[0] = [0 0 0 0 0 1 0 0 0 0], y_train[1] = 0 преобразуется в y_train[1] = [1 0 0 0 0 0 0 0 0 0], а вместо y_train[3] = 1 будет вектор y_train[3] = [0 1 0 0 0 0 0 0 0 0] и так далее. То есть каждое целевое значение будет преобразовано в вектор, состоящий из нулей и одной единицы, позиция которой определяется целевым значением. В Keras произвести такое преобразование можно с помощью функции tensorflow.keras.utils.to_categorical(тензор с данными, количество категорий):
# Преобразуем целевые значения методом «one-hot encoding»
y_train = tensorflow.keras.utils.to_categorical(y_train, 10)
y_test = tensorflow.keras.utils.to_categorical(y_test, 10)
5. Приступаем к написанию модели для решения задачи MNIST в Keras!
После преобразования данных можно приступать к написанию модели. Для построения модели будем использовать обычные полносвязанные слои с разным количеством узлов. В качестве функции активации на входном и промежуточных слоях будем использовать функцию relu. На выходном слое в качестве функции активации определим сигмоиду:
# Создаем модель
model = Sequential([
layers.Dense(32, activation='relu', input_shape=(X_train[0].shape)),
layers.Dense(64, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Flatten(),
layers.Dense(10, activation='sigmoid')
])
# Выведем полученную модель на экран
model.summary()
Результат на экране:
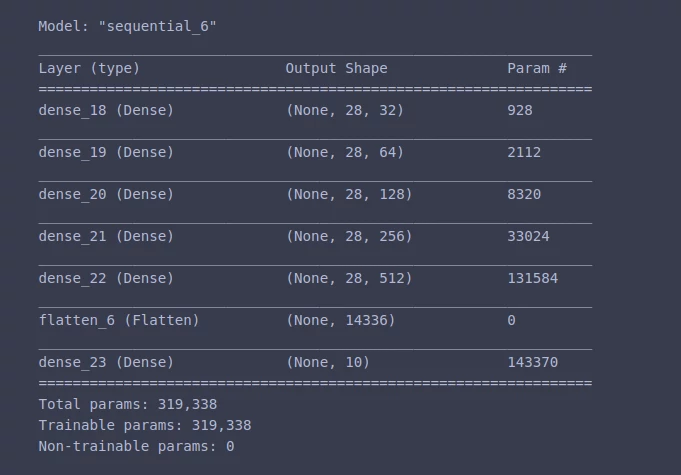
6. Компилируем модель и запускаем обучение
Прежде всего, нам необходимо определить функцию потерь и метрику. Так как целевые значения представляют собой вектора с бинарными значениями(0 или 1) и при этом сумма элементов каждого вектора равна 1, то наиболее удачным выбором, на мой взгляд, представляется метрика ‘binary_accuracy’ и функция потерь ‘binary_crossentropy’. В качестве оптимайзера можно выбрать Adam:
#Компиляция модели
model.compile(loss='binary_crossentropy',
optimizer = Adam(lr=0.00024),
metrics = ['binary_accuracy'])
Кроме того, определим функцию ранней остановки обучения в случае, если в течение 6 эпох потери на валидации (val_loss) не будут уменьшаться:
# Функция ранней остановки
stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', verbose=1, patience=6)
После этого можно смело запускать обучение! Для валидации мы будем использовать 2% данных из X_train и y_train, определим это в параметре validation_split = 0.2. Также установим размер партии с данными, как batch_size=500 и определим количество эпох epochs= 50:
# Запускаем обучение модели
history = model.fit(X_train, y_train, batch_size=500, verbose=1,
epochs= 50, validation_split = 0.2, callbacks=[stop])
На скриншоте ниже приведена часть результатов обучения. Как видно из изображения, после 42 эпохи потери на валидации начинают расти, а это значит, что лучший результат этой нейросети (99,2% на валидации) уже достигнут, и можно останавливать обучение!
7. Проверяем результаты!
А теперь приступим к самому интересному — предсказаниям для тестовой выборки! Результаты с прогнозами сохраним в массиве pred:
# Предсказываем результат для тестовой выборки
pred = model.predict(X_test)
Давайте проверим, в каком виде нейросеть возвращает нам предсказанные данные. Для этого выведем на экран первый элемент массива pred:
print(pred[0])
Результат на экране: [9.9788961e-22, 5.9136482e-09, 1.5235385e-08, 3.8294573e-03, 2.2805100e-13, 1.0801187e-03, 5.8706665e-26, 9.9988544e-01, 3.7852970e-13, 3.9570431e-09]
Нейронная сеть предсказала, что вероятность того, что X_test[0] равен нулю очень мала и составляет 9.9788961e-22. А вот вероятность того, что X_test[0] = 7 составляет 9.9988544e-01, то есть 99.9%.
Напишем небольшой кусок кода для преобразования значений в предсказанных векторах. Заменим на 1 все значения, превышающие 0.5, остальные значения заменим нулем:
for i in range(len(pred)):
for j in range(10):
if(pred[i][j]>0.5):
pred[i][j]=1
else:
pred[i][j]=0
А теперь сравним предсказанное нейросетью значение со значением y_test на примере элемента c индексом 3:
print(pred[3], y_test[3])
Как видно из выведенного на экран результата, предсказанный вектор pred[3] (после преобразования) и целевой вектор y_test[3] совпадают! При желании можно вывести целую партию предсказанных и целевых значений, и даже написать скрипт по их сравнению. Однако, мы не будем разбирать это в рамках данной статьи и оставим дальнейшие преобразования на ваше усмотрение.
Если вы успешно решили задачу MNIST и готовы перейти к более интересным задачам по классификации изображений, рекомендую ознакомиться со статьей «Классификация изображений в Keras — делим фотографии с лицами на мужские и женские с помощью нейросети!». Возможно, она будет вам полезна!
 Фанаты BIG DATЫ — наш Телеграм-канал для всех увлеченных изучением Python, Data Science, ML, нейросетями и т.д. Присоединяйтесь, вместе веселее! 😉
Фанаты BIG DATЫ — наш Телеграм-канал для всех увлеченных изучением Python, Data Science, ML, нейросетями и т.д. Присоединяйтесь, вместе веселее! 😉